Fraud detection using Random Forest
This summer I was determined to learn machine learning algorithms. As one of the first projects, I took up Credit Card Fraud Detection. The data used for this is retrieved from Kaggle.
When I looked at the data, I realised that the data was heavily PCA’d. As you can see, there is no correlation between the features
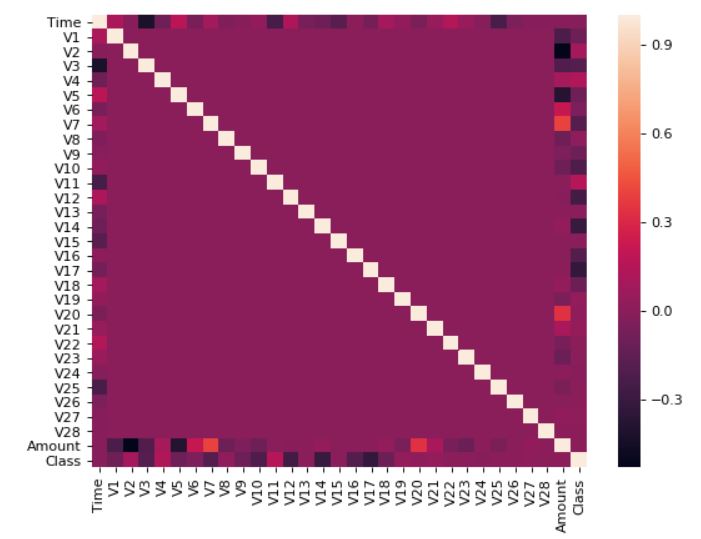
I did get rid of nan values in the dataset.I replaced the nan’s with the average of that column.
I used scikit learn’s random forest classification model to predict the transaction as either a fraud and not fraud. But before doing that, I checked the composition of my data.
I realised that 98% of the transactions were classsified as non-fraud. Running a classification model on such a dataset would result in all or most of the transactions being classified as non-fraud due to the imbalance.
To overcome this, I undersampled the majority class (non-fraud) using the pandas.DataFrame.sample
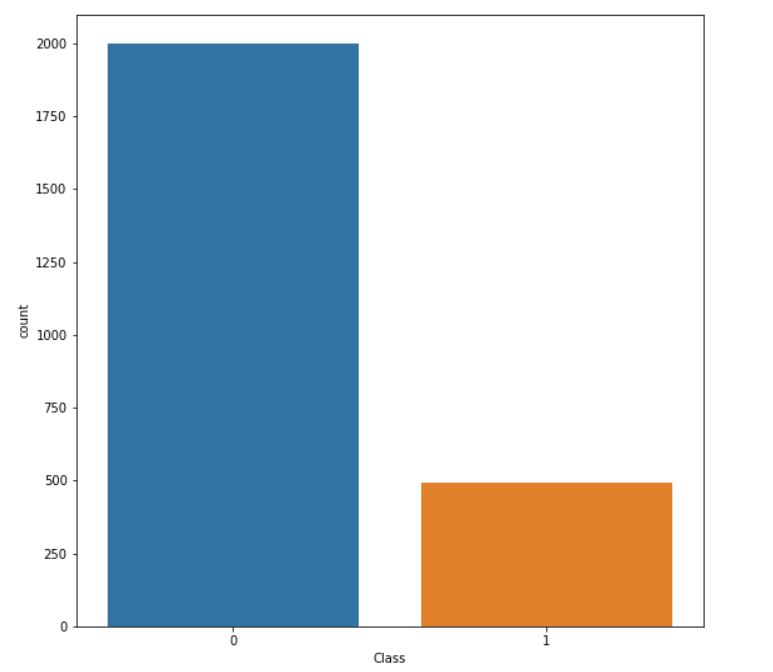
After undersampling, I split the dataset into train and test. I initialised a random forest classifier as such :
clf= RandomForestClassifier(n_estimators= 200, max_depth= 8)
After fitting the training data and predicting on the test data, I got roc_auc_score of 0.9195. I created a method to visualise my test data in a confusion matrix.
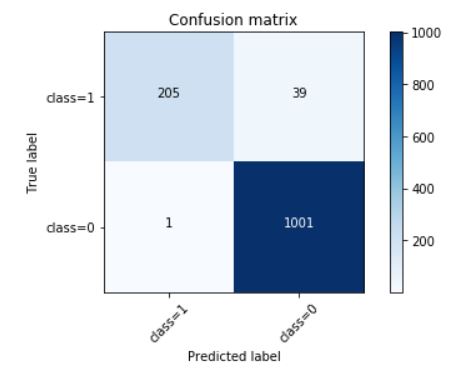
Out of 244 fraud transactions, I predicted 205 of them correctly.
After I was done predicting, I thought of doing transaction analysis using K-Means clustering. I initialised my model as such:
model_= KMeans(init= 'k-means++', n_clusters= 4, n_init= 10)
Most of the fraud transactions, occured for under a certain amount as seen in the image.
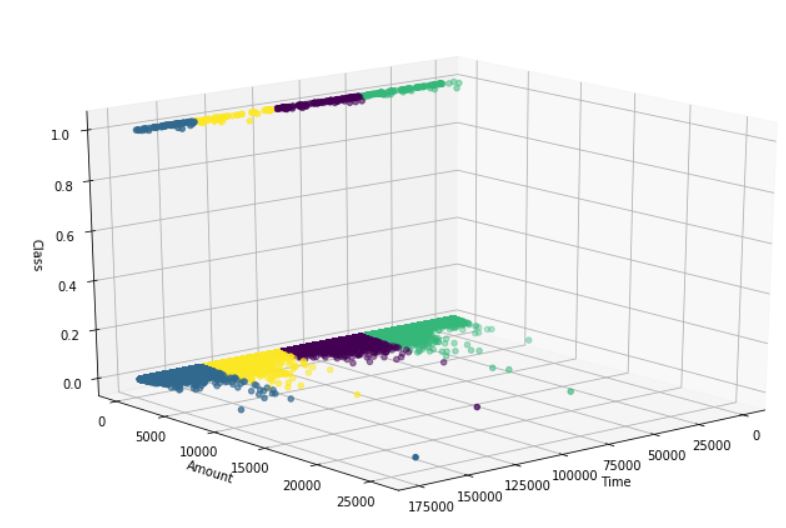
I am currently learning more about K-means clustering and trying to understand the distribution of fraud and non-fraud better.
The code for this project can be found here